Одним из важных для понимания HP Vertica терминов является K-Safety. В этой статье я кратко объясню его суть и покажу как он влияет на хранение данных в БД.
K-Safety — это мера отказоустойчивости БД. Это число, которое определяет количество реплик оригинальных данных внутри кластера БД. В общем случае, если число сбойных нодов внутри кластера будет больше чем это число K, некоторые данные в кластере могут стать недоступными и БД автоматически остановит работу. Однако, в частном случае БД может продолжать работу и при большем количестве сбойных нодов.
Например, если K-Safety вашего кластера = 1 и в нем 6 нодов(1, 2, 3, 4, 5, 6), ноды 2, 4 и 6 могут быть недоступны, но кластер все равно продолжит работу, т.к. копии данных этих нодов будут на других нодах — 3, 5 и 1 соответственно. Это значит, что максимальное количество сбойных нодов при K-Safety = 1 может достигать половины в наилучшем случае и 2(K-Safety+1) в наихудшем.
Существует 3 значения K-Safety, которое поддерживает HP Vertica: 0, 1 и 2.
K-Safety = 0 означает что данные по-умолчанию не будут реплицироваться на соседние ноды, а кластер завершит работу при сбое любого из нодов.
Для распределения данных по кластерам используется их сегментация(Segmentation), а точнее сегментация проекций(Projection) в которых они находятся. Задача разработчика — подобрать такой список полей и/или такую функцию(например, хэш-функцию), благодаря которым данные равномерно распределятся по нодам кластера. HP Vertica рекомендует использовать встроенные функции HASH и MODULARHASH для этих целей.
Для обеспечения K-Safety > 0 создаются сообщные проекции(Buddy Projection). Проекции называются сообщными, если они имеют в себе одинаковые наборы полей и одинаковое выражение сегментации, но хранятся на разных нодах. Сообщные проекции позволяют создать те самые реплики, которые позволяют работать БД в выбранном режиме K-Safety.
Рассмотрим K-Safety, сегментацию, и сообщные проекции на практическом примере.
Дано: Кластер на 3-х нодах. K-Safety = 1.
Создадим простую таблицу.
create table test(n integer primary key);
Вообще, синтаксис создания таблицы позволяет включать в себя выражения влияющие на проекцию(order, hash, ksafe…), для того чтобы проекции создавались автоматически в момент создания таблицы, но в этом примере я создаю проекции вручную.
Далее создадим две сообщные проекции.
create projection p_test_b0 as select n from test order by n segmented by hash(n) all nodes; create projection p_test_b1 as select n from test order by n segmented by hash(n) all nodes offset 1;
Во-первых, выбрано сегментирование по функции hash от поля n. Во-вторых, те же данные, которые хранятся в проекции p_test_b0 на текущем ноде, хранятся в проекции p_test_b1(создана с offset 1) на следующем ноде. Иными словами текущий нод содержит в сегменте проекции p_test_b1 данные предыдущего нода. Пока может быть не очень понятно, ниже покажу на рисунке.
Если захотите сделать опыт и создать только одну проекцию, получите ошибку =) Одной проекции недостаточно для обеспечения K-Safety = 1.
Здесь же отмечу, что выражение сортировки order by у сообщных проекций не обязательно должно совпадать. Благодаря этому вы сможете совместить приятное с полезным — обеспечить K-Safety и оптимизировать выполнение многообразных запросов, выполняемых в системе.
Вставим тестовые данные:
insert into test values(1); insert into test values(2); insert into test values(3); insert into test values(4); insert into test values(5); insert into test values(6); insert into test values(7); insert into test values(8); insert into test values(9); insert into test values(10);
И посмотрим как они распределились по нодам:
select node_name, projection_name, row_count from projection_storage where projection_name like 'p_test_b%' order by node_name, projection_name;
v_antifraud_node0001 p_test_b0 1 v_antifraud_node0001 p_test_b1 4 v_antifraud_node0002 p_test_b0 5 v_antifraud_node0002 p_test_b1 1 v_antifraud_node0003 p_test_b0 4 v_antifraud_node0003 p_test_b1 5
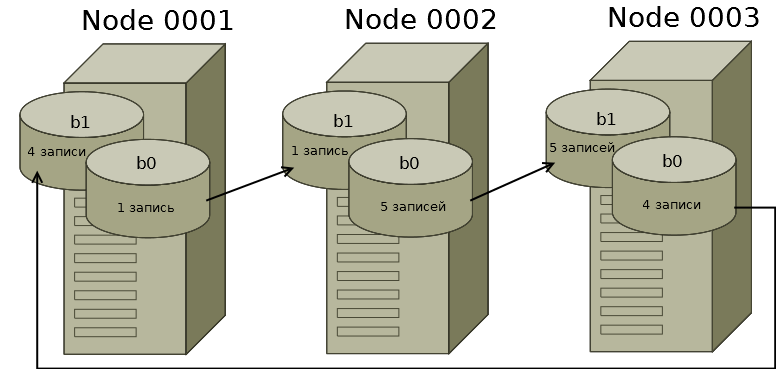
Итак, имеем 10 строк. Благодаря хэш-функции данные в проекции p_test_b0 распределились следующим образом: 1 строка на ноде 1, 5 на ноде 2 и 4 на ноде 3. При этом благодаря параметру «offset 1» объявленному в проекции p_test_b1 данные, которые уже хранятся на текущем ноде, хранятся и на следующем.
Аналогичным образом можно было создать проекции для кластера с K-Safety = 2, создав при этом третью сообщную проекцию, и указав для неё желаемый offset, например 2. В случае с тремя нодами при K-Safety = 2 все данные хранились бы на всех нодах.
Надеюсь теперь вам понятен принцип, по которому распределяются данные внутри кластера в зависимости от K-Safety.
P.S: На деле проекции можно так же создавать на выбранных нодах, перечислив их номера в команде создания проекции. Также можно не создавать проекции по отдельности, а добавить при создании первой проекции параметр ksafe — вторая создастся автоматически.